导入包最好使用绝对路径
环境变量:import sys
sys.path获取路径列表
添加父级路径
import sys ,os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #__file__的是打印当前被执行的模块.py文件相对路径,注意是相对路径 print(BASE_DIR)
sys.path.append(BASE_DIR)
包就是文件夹,但该文件夹下必须存在 init.py 文件, 该文件的内容可以为空。int.py用于标识当前文件夹是一个包。
常用模块
1.time&datetime模块
time
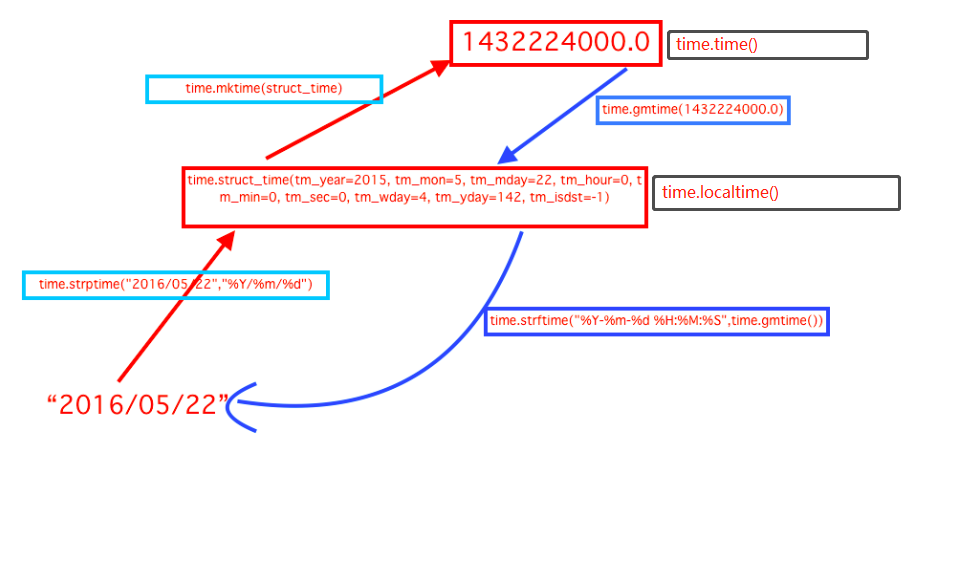
datetime相比于time模块,datetime模块的接口则更直观、更容易调用

random随机数模块
>>> random.randrange(1,10) #返回1-10之间的一个随机数,不包括10
>>> random.randint(1,10) #返回1-10之间的一个随机数,包括10
>>> random.randrange(0, 100, 2) #随机选取0到100间的偶数
>>> random.random() #返回一个随机浮点数
>>> random.choice('abce3#$@1') #返回一个给定数据集合中的随机字符
'#'
>>> random.sample('abcdefghij',3) #从多个字符中选取特定数量的字符
['a', 'd', 'b']
#生成随机字符串
>>> import string
>>> ''.join(random.sample(string.ascii_lowercase + string.digits, 6))
'4fvda1'
#洗牌
>>> a
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> random.shuffle(a)
>>> a
[3, 0, 7, 2, 1, 6, 5, 8, 9, 4]
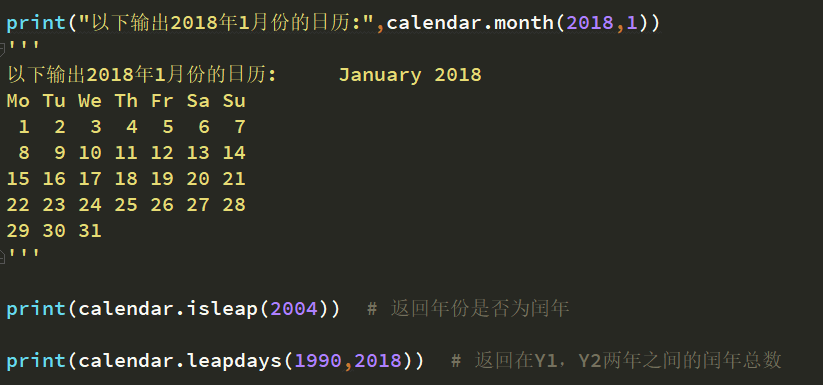
calendar日历模块
 os模块提供了很多允许你的程序与操作系统直接交互的功能
os模块提供了很多允许你的程序与操作系统直接交互的功能
注意!py3中修改文件名,多用于文件操作os.replace(“newname”,”oldname”)
os大全:
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
os.path.normcase(path) 小写返回path
os.path.normpath(path) 规范化返回,给定路径上不识别的路径抛弃,或者处理..返回上一层
os.walk() 可以得到一个三元tupple(dirpath, dirnames, filenames):https://blog.csdn.net/bagboy_taobao_com/article/details/8938126
 dirpath 是一个string,代表目录的路径,
 dirnames 是一个list,包含了dirpath下所有子目录的名字。
 filenames 是一个list,包含了非目录文件的名字。
 这些名字不包含路径信息,如果需要得到全路径,需要使用os.path.join(dirpath, name).
 通过for循环自动完成递归枚举
sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:') #标准输出 , 引出进度条的例子, 注,在py3上不行,可以用print代替
val = sys.stdin.readline()[:-1] #标准输入
sys.getrecursionlimit() #获取最大递归层数
sys.setrecursionlimit(1200) #设置最大递归层数
sys.getdefaultencoding() #获取解释器默认编码
sys.getfilesystemencoding #获取内存数据存到文件里的默认编码
shutil模块
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
shutil.copyfile(src, dst)
拷贝文件
shutil.copyfile('f1.log', 'f2.log') #目标文件无需存在
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copymode('f1.log', 'f2.log') #目标文件必须存在
shutil.copystat(src, dst)
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('f1.log', 'f2.log') #目标文件必须存在
shutil.copy(src, dst)
拷贝文件和权限
shutil.copy('f1.log', 'f2.log')
shutil.copy2(src, dst)
拷贝文件和状态信息
shutil.copy2('f1.log', 'f2.log')
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的
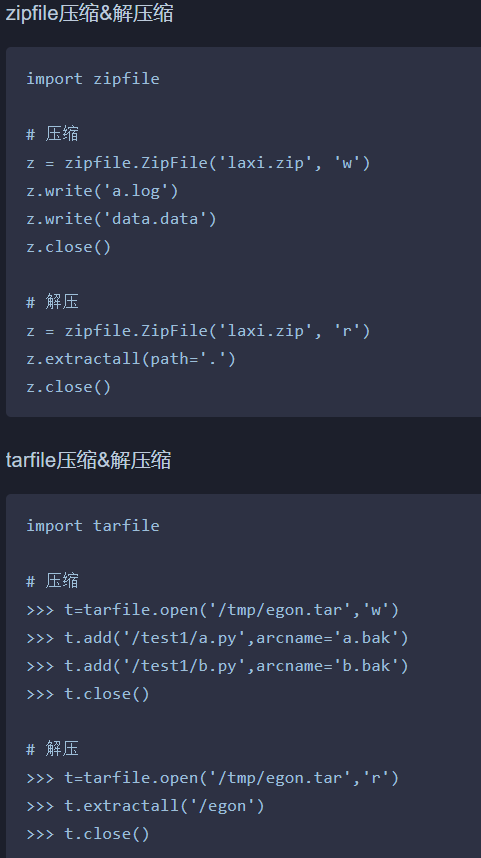
序列化模块json/pickle/xml/shelve
json/pickle使用方法相同,区别:json能跨语言传输,pickle只能用于python语言

xml:https://www.luffycity.com/python-book/di-4-zhang-python-ji-chu-2014-chang-yong-mo-kuai/xml-mo-kuai.html
shelve模块:shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
Configparser配置文件模块
用于生成和修改常见配置文档:
hashlib模块
01.hashlib使用

02.加盐SALT
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
1 import hashlib
2 p = hashlib.md5('password'.encode('utf-8)) 在hashlib.md5( salt )加盐
3 p.update('123456'.encode('utf-8')
4 print(p.hexdigest())
subprocess模块:https://www.luffycity.com/python-book/di-4-zhang-python-ji-chu-2014-chang-yong-mo-kuai/subprocess-mo-kuai.html
通过Python去执行一条系统命令或脚本,类似于os.system
logging日志模块
5个日志等级:debug(), info(), warning(), error() and critical()
日志模块基础使用流程:import logging
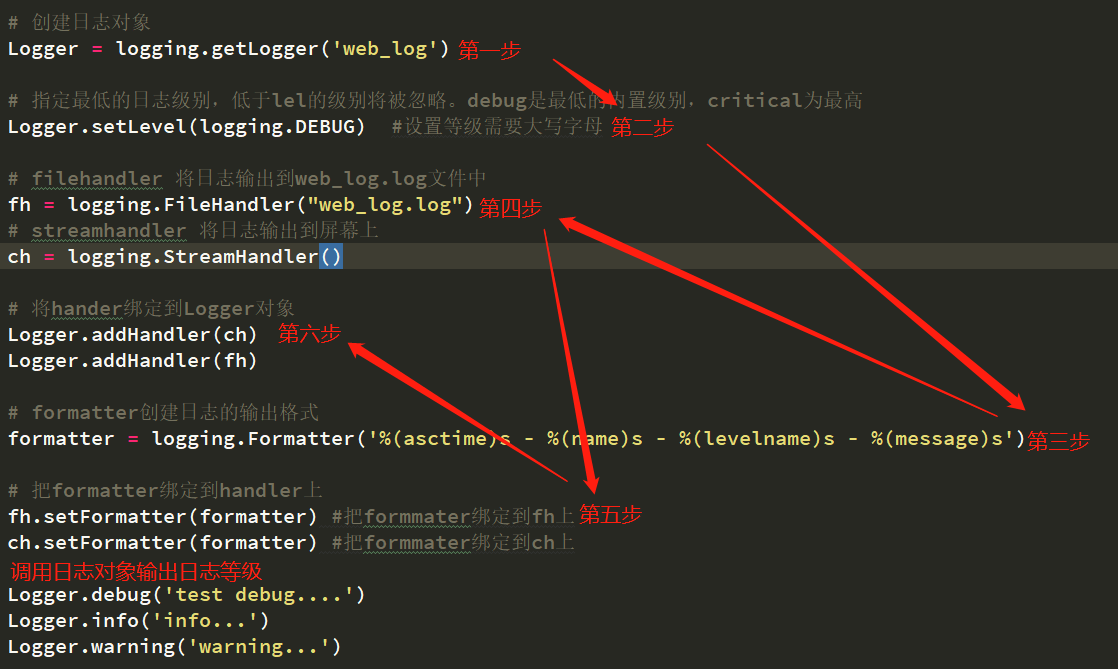
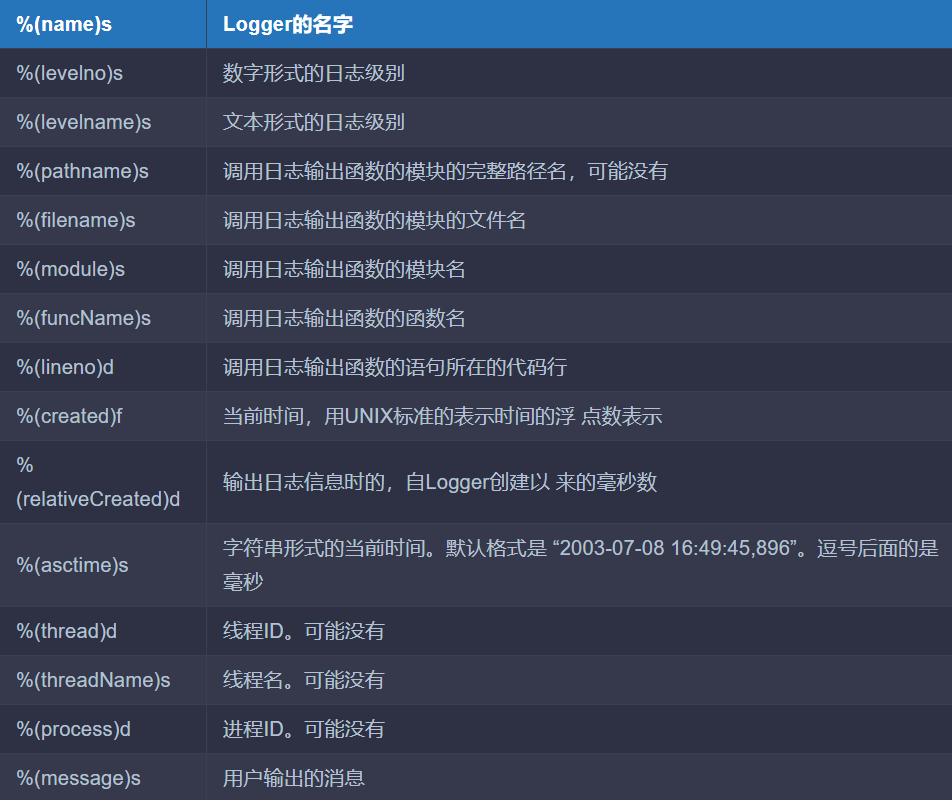
日志输出格式formatter参数
python日志重复输出问题解决方法:
https://www.jianshu.com/p/92aa9b1ce9e7
re正则模块
常用表达式规则

re的匹配语法有以下几种
返回一个re对象: <_sre.SRE_Match object; span=(0, 1), match=’a’> span为长度;match为匹配到的值,需要通过.group(num)获取匹配到的值(match=的值),num默认为空,可以通过赋值,获取分组匹配()中对应的值
re.match 从头开始匹配
re.search 匹配包含
返回一个匹配元素的列表
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.split 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
示例:

re.fullmatch 全部匹配
整个字符串匹配成功就返回re object, 否则返回None
re.fullmatch('\w+@\w+\.(com|cn|edu)',"alex@oldboyedu.cn")
Flags修饰符
默认re匹配语法第三个参数为flags=0
多个修饰符可以通过 |&等符号进行链接
