markdown学习目录
Markdown是什么?
为什么使用Markdown?
常用工具
常用语法
深入研究
在Django中实现markdown
正文
1.Markdown是什么?
Markdown是一种轻量级标记语言,它以纯文本形式(易读、易写、易更改)编写文档,并最终以HTML格式发布。Markdown也可以理解为将以MARKDOWN语法编写的语言转换成HTML内容的工具。
2.为什么使用Markdown?
- 简单易读、语法简洁、学习成本低、实用度高
- 兼容HTML
- 很多网站支持markdown
- 在开发中也有很多开源的markdown编译器提供给我们开发者
3.常用工具
Windows:马克飞象(免费/付费两个版本。与印象笔记同步数据)
Mac:Mou、Macdown
Linux:ReText
在线:dillinger、简书、GitHub、马克飞象
扩展工具:Evernote Web Clipper(Chrome扩展工具需要翻墙,用于快速裁剪网页到印象笔记中)、Simple Free Image Hosting(图床工具)、Jupyternotebook(python使用者可选工具)
4.常用语法
Markdown语法主要分为如下几大部分: 标题,段落,区块引用,代码区块,强调,列表,分割线,链接,图片,反斜杠 \,符号。
4.1 标题
语法
# h1级标题
## h2级标题
### h3级标题
#### h4级标题
##### h5级标题
###### h6级标题
效果
h1级标题
h2级标题
h3级标题
h4级标题
h5级标题
h6级标题
4.2 段落
段落前后必须有空行,强制换行必须在末尾加两个“空格”
如果要使用缩进,则使用 ,可以使用多个 进行多个缩进
使用其他语法(如,、-、1、>等,在最后一行一定要留一个空行)
*注意:预览时看上去不加空格一样可以回车空行,但是在转换成HTML时,则不会换行
4.3引用
在段落的每行或者只在第一行使用符号>,还可使用多个嵌套引用
语法
> 这是第一级引用。
>
> > 这是第二级引用。
>
> 现在回到第一级引用。
效果
这是第一级引用。
这是第二级引用。
现在回到第一级引用。
引用可以和其他语法嵌套使用
语法
> ## 这是一个标题。
> 1. 这是第一行列表项。
> 2. 这是第二行列表项。
>
> 给出一些例子代码:
>
> return shell_exec(`echo $input | $markdown_script`);
效果
这是一个标题。
- 这是第一行列表项。
- 这是第二行列表项。
给出一些例子代码:
return shell_exec(
echo $input | $markdown_script);
4.4 代码块
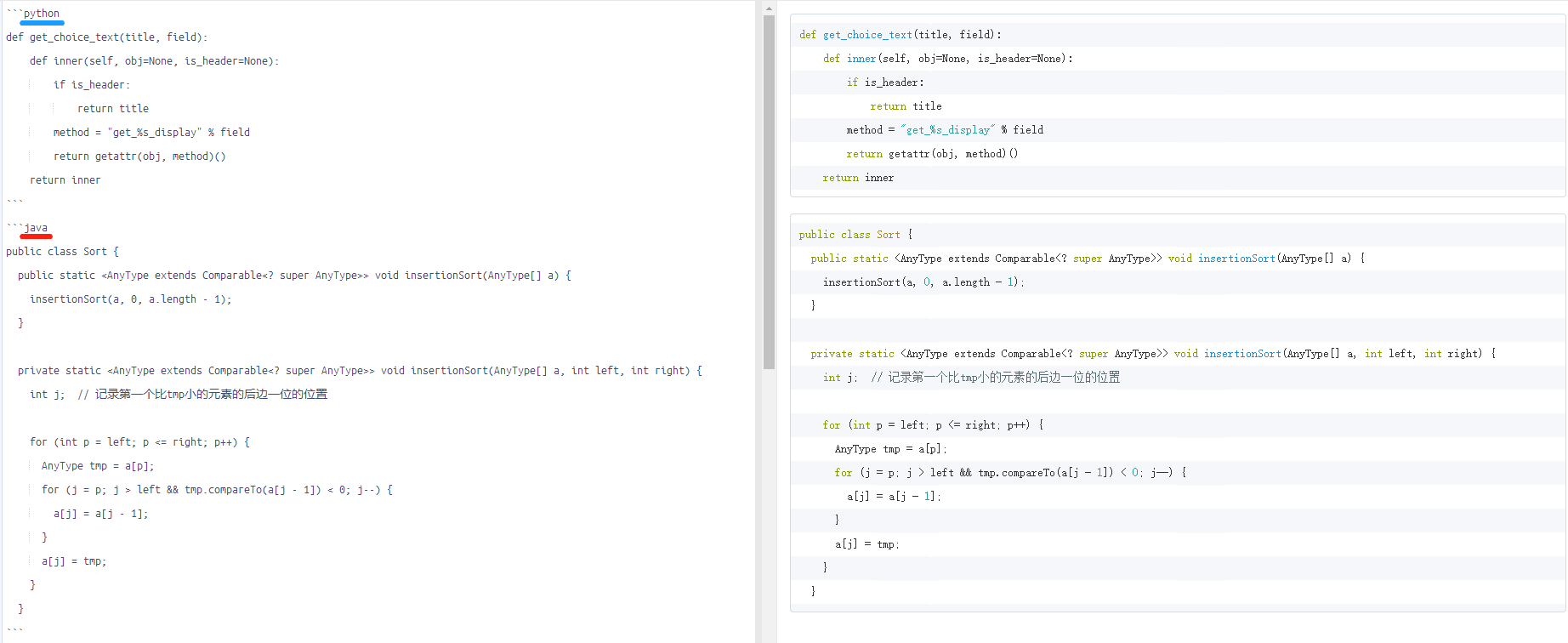
只要把你的代码块包裹在 ` 之间(反引号,需要切成英文输入法),你就不需要通过无休止的缩进来标记代码块了。 在围栏式代码块中,你可以指定一个可选的语言标识符,然后我们就可以为它启用语法着色了。快捷键Ctrl+K
语法
单行代码:1个`包围代码
多行代码:3个`包围代码
效果
4.5 强调
语法:在强调内容两侧分别加上*或者_
*斜体*,_斜体_
**粗体**,__粗体__
***斜体粗体***,可以组合使用
注意!切记强调语句的末尾和头部不能有特殊符号
效果
斜体,斜体
粗体,粗体
4.6 列表
使用*、+、或-标记无序列表,如:
-(+) 第一项 -(+) 第二项 - (+*)第三项
注意:标记后面最少有一个_空格_或_制表符_。若不在引用区块中,必须和前方段落之间存在空行。
效果
- 第一项
- 第二项
- 第三项
有序列表的标记方式是将上述的符号换成数字,并辅以.,如:
- 第一项
- 第二项
- 第三项
注意:.后一定要加至少一个空格
4.7分割线
语法:三个及以上的 * 、 - 、_
4.8链接
链接可以由两种形式生成:行内式和参考式。
行内式:
[跳转我的博客](http://qqlblog.cc/)
效果
参考式:
[python算法1][1]
[python算法2][2]
[1]:http://qqlblog.cc/2018/10/04/Python-%E7%AE%97%E6%B3%95/
[2]:http://qqlblog.cc/2018/10/05/Python-%E7%AE%97%E6%B3%952/
效果
注意:上述的[1]xxxxx/[2]xxxxx不会显示在页面中
4.9锚点
实现类似于目录的跳转
markdown语法给每一个#号开头的字段添加了一个id = 当前字段的文本,如:
# 目录头部 ----转换成HTML----> 多了一个 id=目录头部 的属性
# 目录中部 ----转换成HTML----> 多了一个 id=目录中部 的属性
# 目录尾部 ----转换成HTML----> 多了一个 id=目录尾部 的属性
注意:使用第三方的markdown编译器转换成HTML标签时,id会等于一个不同的前缀加文本内容
锚点的本质就是链接跳转,语法和链接类似:
[点击跳转到顶部](#markdown学习目录)
注意:[]内写在页面打印的文本,(#)内填写链接id内容。其中id内容字母需要全部转为小写,如果有空格则用-进行替换,如果有其他特殊符号(例如标点符号),则删掉特殊符号
效果
4.10 图片
图片和链接相似只需在链接的基础上在最前端添加一个!
语法

注意:markdown如果在本地编辑,图片使用的本地图片,则需要添加到图床上,防止图片失效。如需防止爬虫爬取图片,则可以在nginx上设置防盗链。
4.11 表格
语法
First Header | Second Header | Third Header
------------ | ------------- | ------------
Content Cell | Content Cell | Content Cell
Content Cell | Content Cell | Content Cell
效果
| First Header | Second Header | Third Header |
|---|---|---|
| Content Cell | Content Cell | Content Cell |
| Content Cell | Content Cell | Content Cell |
也可以让表格两边内容对齐,中间内容居中,由 : 控制,例如:
First Header | Second Header | Third Header
:----------- | :-----------: | -----------:
Left | Center | Right
Left | Center | Right
效果
| First Header | Second Header | Third Header |
|---|---|---|
| Left | Center | Right |
| Left | Center | Right |
4.12自动生成目录
语法
[TOC] 自动根据markdown中的所有‘#’开头的语法生成对应锚点的目录
5.深入研究
markdown语法对应的HTML标签
5.1标题
# 一级标题 <h1> 一级标题 </h1>
## 二级标题 <h2> 二级标题 </h2>
### 三级标题 <h3> 三级标题 </h3>
5.2文字格式
*这是斜体1* <em> 这是斜体1 </em>
_这是斜体2_ <i> 这是斜体2 </i>
5.3粗体
**这是粗体1** <strong>这是粗体1</strong>
__这是粗体2__ <b>这是粗体2</b>
5.4引用
> 神说、要有光、就有了光
>> 神看光是好的、就把光暗分开了。
-----对应------
<blockquote>神说、要有光、就有了光<blockquote>神看光是好的、就把光暗分开了。</blockquote></blockquote>
5.5删除线
~~This is strikethrough,only for GFM.~~
-----对应------
<del>This is strikethrough,only for GFM.</del>
5.6代码
单行:
`var i=10;` <code>var i=10;</code>
多行代码:
三组` <pre></pre>
5.7分割线
--- <hr />
5.8列表
无序:
* 行1
* 行2
* 行3
-------对应--------
<ul>
<li>行1</li>
<li>行2</li>
<li>行3</li>
</ul>
有序:
1. 行1
2. 行2
3. 行3
-------对应-------
<ol>
<li>行1</li>
<li>行2</li>
<li>行3</li>
</ol>
5.9链接
[点击跳转博客](http://qqlblog.cc) <a href="http://qqlblog.cc">点击跳转博客</a>
5.10图片

------对应------
<img src="https://github.com/images/modules/contact/heartocat.png" alt="github"/>
5.11表格
| ID | name | salary |
|--------|:----------------:|----------:|
| 1 | lqq | 200000 |
| 2 | qql | 400000 |
-----对应------
<table border='1' summary="2015年xx学校xx年级">
<thead>
<tr>
<th>ID</th>
<th>name</th>
<th>salary</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>lqq</td>
<td>200000</td>
</tr>
<tr>
<td>2</td>
<td>qql</td>
<td>400000</td>
</tr>
</tbody>
</table>
6.在Django中实现markdown
6.1安装markdown包
pip install markdown
6.2在Django中,转换markdown文本为HTML本质上是从显示文本入手,即把保存在数据库中用markdown语法写的文章读取出来,在后端经过markdown模块的操作,再渲染到前端页面中。
models.py
class Post(models.Model):
"""
文章详情
"""
title = models.CharField(verbose_name="标题", max_length=70)
body = models.TextField(verbose_name="内容")
created_time = models.DateTimeField(verbose_name="创建时间", auto_now_add=True)
# 最后一次修改时间
modified_time = models.DateTimeField(verbose_name="修改时间",auto_now_add=True)
# 摘要
excerpt = models.CharField(verbose_name="摘要",max_length=200, null=True, help_text="文章摘要")
category = models.ForeignKey(verbose_name="分类",to=Category, on_delete=models.CASCADE)
tags = models.ManyToManyField(verbose_name="标签", to = Tag, blank=True)
author = models.ForeignKey(verbose_name="作者", to = User, on_delete=models.CASCADE)
urls.py
re_path(r'^post/(?P<pk>[0-9]+)/$', views.detail, name='detail'),
views.py
# Markdown 内置的处理方法不能处理中文标题, slugify用于处理中文
from django.utils.text import slugify
# TocExtension 在实例化时其 slugify 参数可以接受一个函数作为参数,这个函数将被用于处理标题的锚点值。
from markdown.extensions.toc import TocExtension
def detail(request, pk):
"""
文章详情v1.0
:param request:
:param pk:
:return:
"""
# 当传入的 pk 对应的 Post 在数据库存在时,就返回对应的 post,
# 如果不存在,就给用户返回一个 404 错误,表明用户请求的文章不存在。
post = get_object_or_404(models.Post, pk=pk)
post.body = markdown.markdown(post.body,
extensions=[
'markdown.extensions.extra',
'markdown.extensions.codehilite', # highlight
# 'markdown.extensions.toc', # toc自动生成目录
TocExtension(slugify=slugify),
])
form = CommentForm()
comment_list = post.comment_set.all()
# 将文章、表单、以及文章下的评论列表作为模板变量传给 detail.html 模板,以便渲染相应数据。
context = {'post': post,
'form': form,
'comment_list': comment_list
}
return render(request, 'detail.html', context=context)
前端页面